
概述
进程间有哪些通信方式?
- 管道
- 消息队列
- 共享内存
- 信号量
- 信号
- Socket
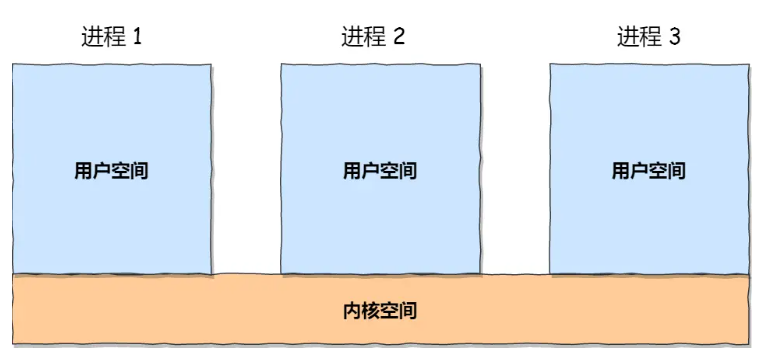
每个进程的用户地址空间都是独立的,一般而言是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核
1.管道
1 | ps auxf | grep mysql |
上面命令行里的「|」竖线就是一个管道,它的功能是将前一个命令(ps auxf)的输出,作为后一个命令(grep mysql)的输入,从这功能描述,可以看出管道传输数据是单向的,如果想相互通信,我们需要创建两个管道才行。
同时,我们得知上面这种管道是没有名字,所以「|」表示的管道称为匿名管道,用完了就销毁。
管道还有另外一个类型是命名管道,也被叫做 FIFO,因为数据是先进先出的传输方式。
1.1.命名管道
创建和使用命名管道
在使用命名管道前,先需要通过mkfifo命令来创建,并且指定管道名字:
1 | mkfifo myPipe |
接下来,我们往myPipe这个管道写入数据:
1 | echo "hello" > myPipe // 将数据写进管道 |
你操作了后,你会发现命令执行后就停在这了,这是因为管道里的内容没有被读取,只有当管道里的数据被读完后,命令才可以正常退出。
于是,我们执行另外一个命令来读取这个管道里的数据:
1 | $ cat < myPipe // 读取管道里的数据 |
可以看到,管道里的内容被读
我们可以看出,管道这种通信方式效率低,不适合进程间频繁地交换数据。当然,它的好处,自然就是简单,同时也我们很容易得知管道里的数据已经被另一个进程读取了。取出来了,并打印在了终端上,另外一方面,echo 那个命令也正常退出了
1.2.匿名管道
管道如何创建,背后的原理是什么?
匿名管道的创建,需要通过下面这个系统调用:
1 | int pipe(int fd[2]) |
这里表示创建一个匿名管道,并返回了两个描述符,一个是管道的读取端描述符fd[0],另一个是管道的写入端fd[1]。注意,这个匿名管道是特殊的文件,只存在于内存
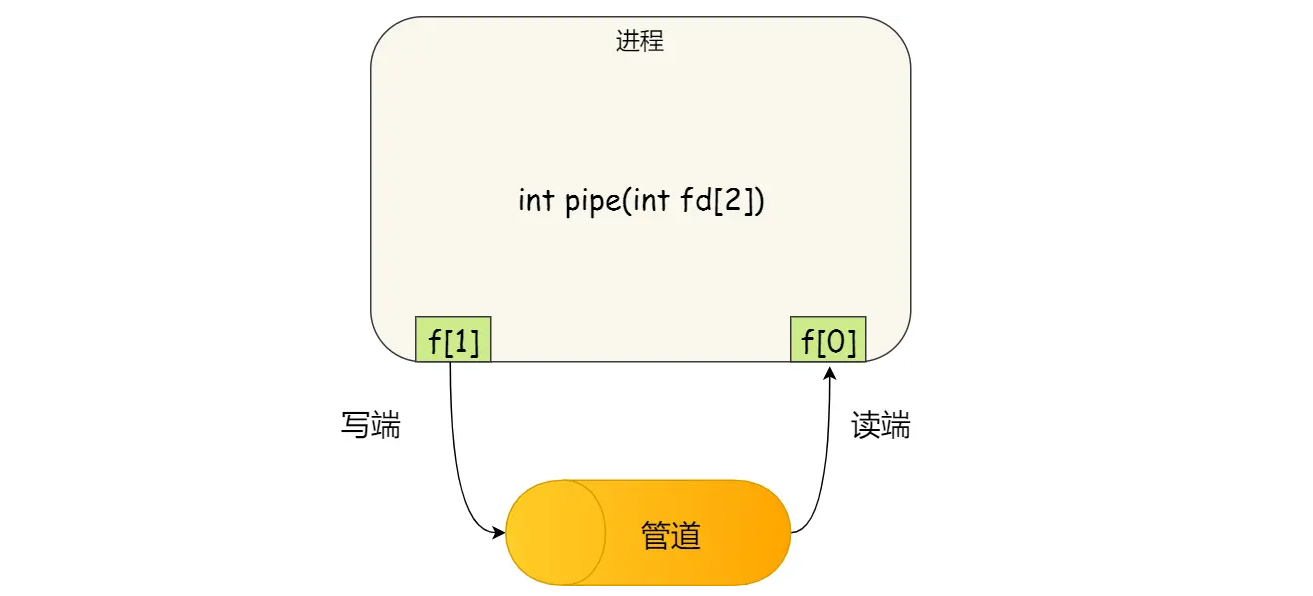
所谓的管道,就是内核里面的一串缓存,从管道的一段写入的数据,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据,另外管道传输的数据是无格式的流且大小受限
两个描述符都是在一个进程里面,并没有起到进程间通信的作用,怎么才能使得管道是跨过两个进程的呢?
我们可以使用fork创建子进程,创建的子进程会复制父进程的文件描述符,这样就做到了两个进程各有两个 fd[0] 与 fd[1],两个进程就可以通过各自的fd写入和读取同一个管道文件实现跨进程通信了
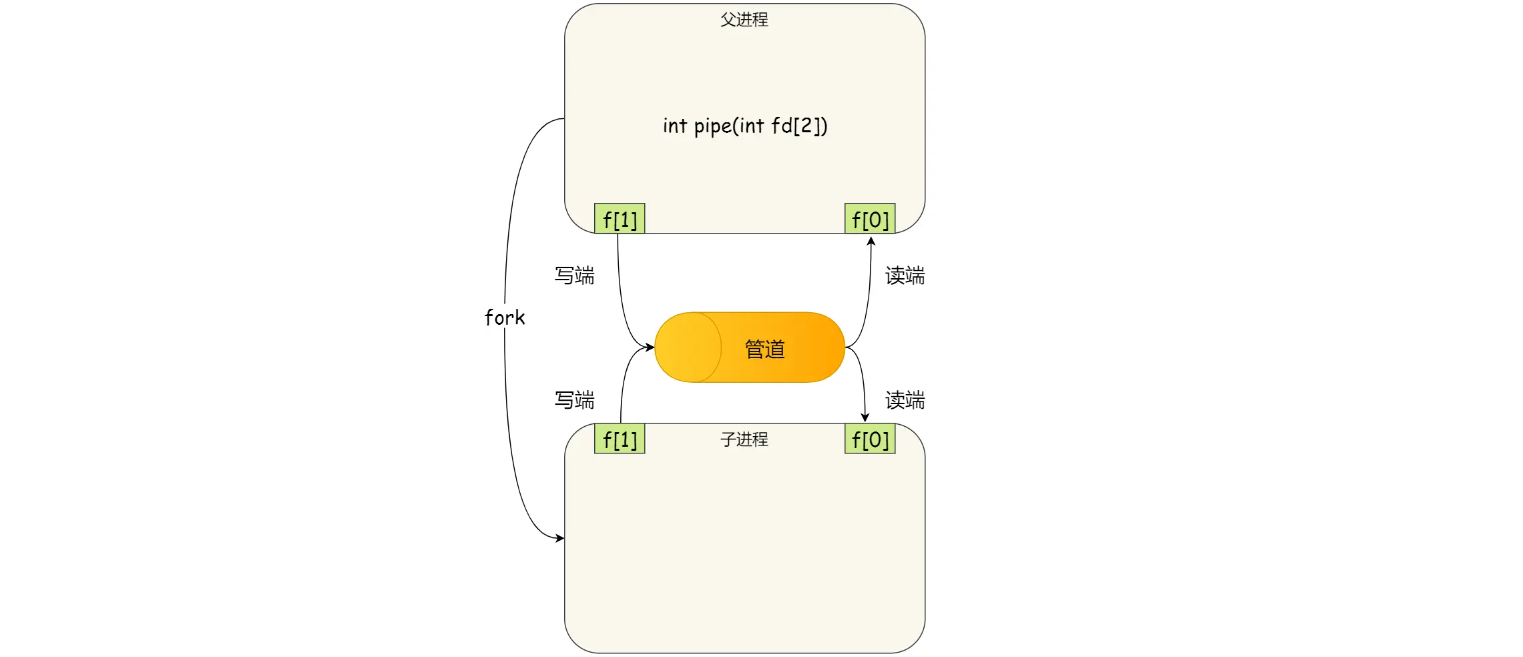
管道只能一段写如,另一个端读出,所以上面这种模式容易造成混乱,因为父进程和子进程都可以同时写入,也都可以读出,那么,为了避免这种情况,通常的做法是:
- 父进程关闭读取的 fd[0],只保留写入的 fd[1];
- 子进程关闭写入的 fd[1],只保留读取的 fd[0];
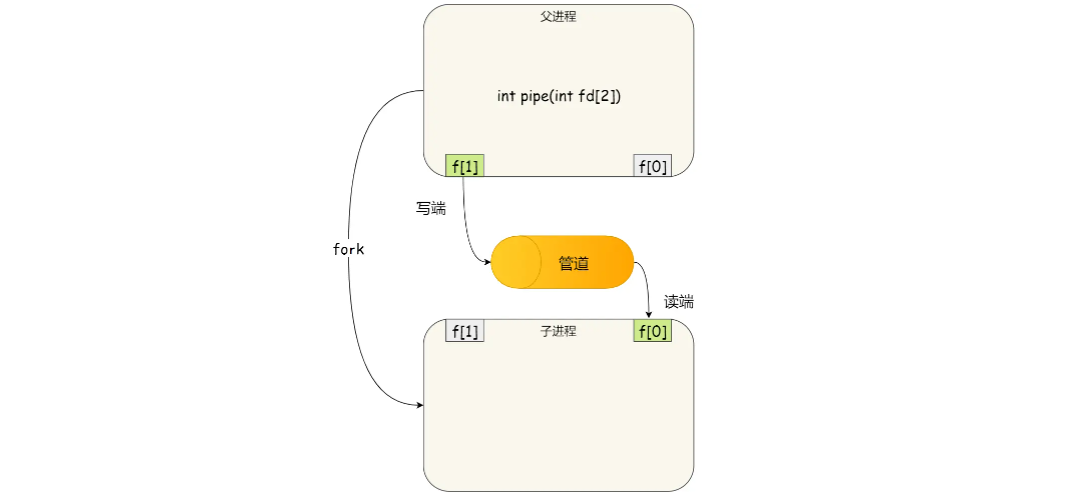
所以说如果需要双向通信,则应该创建两个管道
到这里,我们仅仅解析了使用管道进行父进程与子进程之间的通信,但是在我们 shell 里面并不是这样的。
在 shell 里面执行 A | B命令的时候,A 进程和 B 进程都是 shell 创建出来的子进程,A 和 B 之间不存在父子关系,它俩的父进程都是 shell。
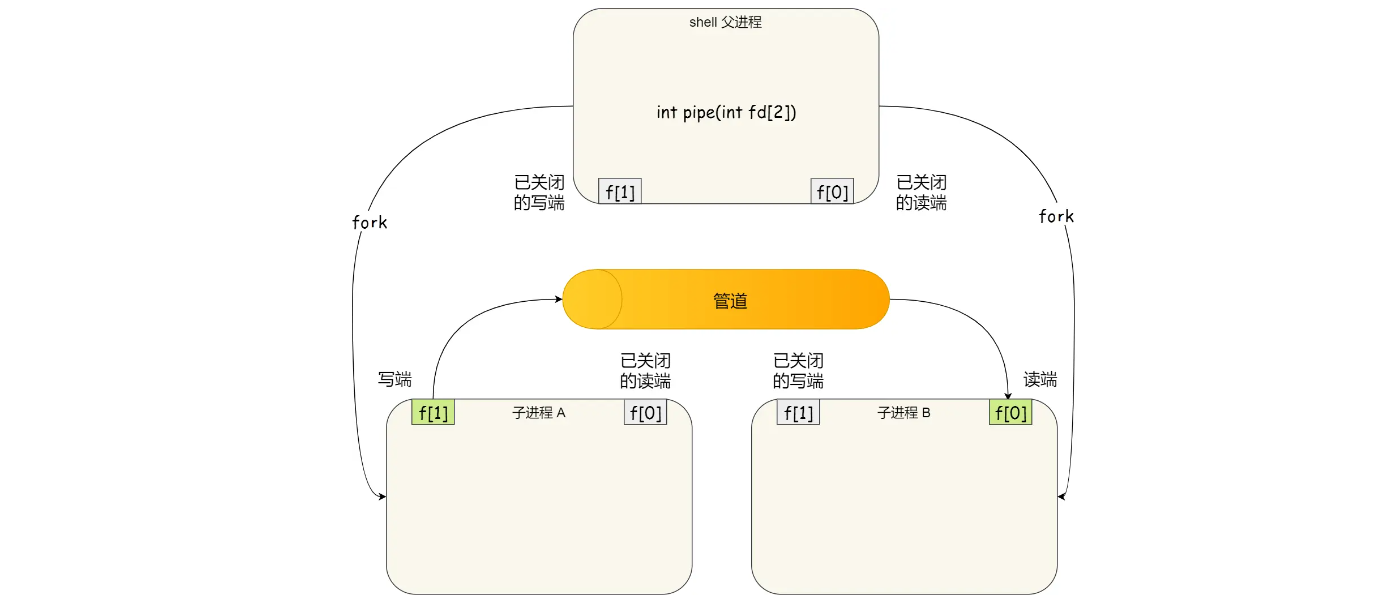
所以说,在 shell 里通过「|」匿名管道将多个命令连接在一起,实际上也就是创建了多个子进程,那么在我们编写 shell 脚本时,能使用一个管道搞定的事情,就不要多用一个管道,这样可以减少创建子进程的系统开销
对于匿名管道,它的通信范围是存在父子关系的进程。因为管道没有实体,也就是没有管道文件,只能通过fork来复制父进程fd文件描述符,来达到通信的目的
不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则
2.消息队列
消息队列通信模式:A进程要给B进程发送消息,A进程把数据放在对应的消息队列后就可以正常返回,B进程需要的时候再去读取数据就可以了。同理,B进程要给A进程发送消息也是如此
消息队列是保存在内核中的消息链表;
消息体:发送方和接收方约定好的数据类型
在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型;所以,每个消息体都是固定大小的存储块;
缺点:
- 通信不及时
- 附件大小有限制
- 不适合比较大的数据传输,因为在内核中每个消息体都有一个最大长度的限制
- 消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销
3.共享内存
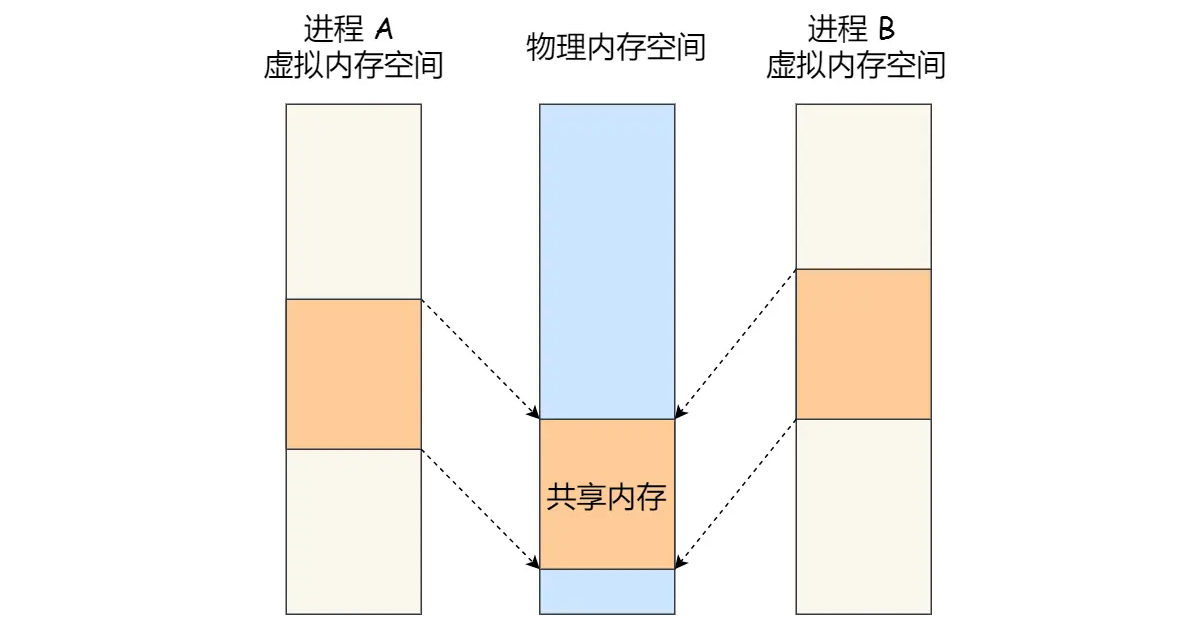
消息队列的读取和写入的过程,都会有发生用户态与内核态之间的消息拷贝过程。那共享内存的方式,就很好的解决了这一问题。
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中
这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去,大大提高了进程间通信的速度
4.信号量
共享内存通信方式,带来新的问题,那就是如果多个进程同时修改同一个共享文件,很有可能冲突了,例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了
为了防止多进程竞争共享资源,而造成的数据错乱,所以需要保护机制,使得共享的资源,在任意时刻之恶能被一个进程访问。正好,信号量就实现了这一保护机制
信号量其实是一个整形的计数器,主要用于实现进程间的互斥与同步,而不是用于缓存进程间的数据
信号量表示资源的数量,控制信号量的方式有两种原子操作:
- P操作:信号量减一,相减后如果信号量 < 0,则表示资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可以正常继续执行
- V操作: 信号量加一,相加后如果信号量<= 0,则表示当前有阻塞中的进程,于是会将该进程唤醒运行,相加后如果信号量 > 0,则表明当前没有阻塞中的进程
P操作使用在进入共享资源之前,V操作是用在离开共享资源之后,这两个操作是必须成对出现的
接下来,举个例子,如果要使得两个进程互斥访问共享内存,我们可以初始化信号量为 1。
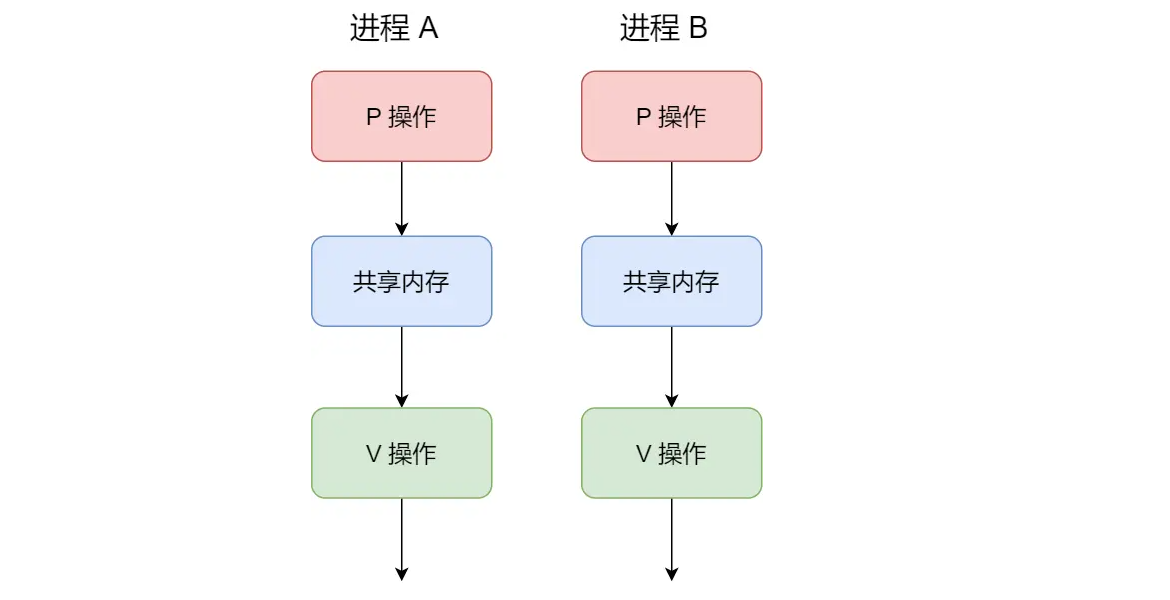
具体的过程如下:
- 进程 A 在访问共享内存前,先执行了 P 操作,由于信号量的初始值为 1,故在进程 A 执行 P 操作后信号量变为 0,表示共享资源可用,于是进程 A 就可以访问共享内存。
- 若此时,进程 B 也想访问共享内存,执行了 P 操作,结果信号量变为了 -1,这就意味着临界资源已被占用,因此进程 B 被阻塞。
- 直到进程 A 访问完共享内存,才会执行 V 操作,使得信号量恢复为 0,接着就会唤醒阻塞中的线程 B,使得进程 B 可以访问共享内存,最后完成共享内存的访问后,执行 V 操作,使信号量恢复到初始值 1。
可以发现,信号初始化为 1,就代表着是互斥信号量,它可以保证共享内存在任何时刻只有一个进程在访问,这就很好的保护了共享内存。
另外,在多进程里,每个进程并不一定是顺序执行的,它们基本是以各自独立的、不可预知的速度向前推进,但有时候我们又希望多个进程能密切合作,以实现一个共同的任务。
例如,进程 A 是负责生产数据,而进程 B 是负责读取数据,这两个进程是相互合作、相互依赖的,进程 A 必须先生产了数据,进程 B 才能读取到数据,所以执行是有前后顺序的。
那么这时候,就可以用信号量来实现多进程同步的方式,我们可以初始化信号量为 0。
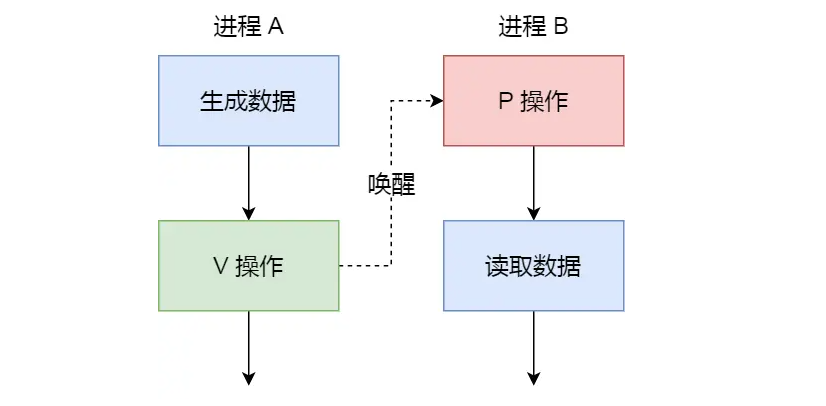
具体过程:
- 如果进程 B 比进程 A 先执行了,那么执行到 P 操作时,由于信号量初始值为 0,故信号量会变为 -1,表示进程 A 还没生产数据,于是进程 B 就阻塞等待;
- 接着,当进程 A 生产完数据后,执行了 V 操作,就会使得信号量变为 0,于是就会唤醒阻塞在 P 操作的进程 B;
- 最后,进程 B 被唤醒后,意味着进程 A 已经生产了数据,于是进程 B 就可以正常读取数据了。
可以发现,信号初始化为 0,就代表着是同步信号量,它可以保证进程 A 应在进程 B 之前执行。
5.信号
信号是异步通信机制,信号可以在应用进程和内核之间直接交互
可以在在任何时候发送信号给某一个进程,一旦有信号产生,我们就有下面这几种,用户进程对信号的处理方式
- 执行默认操作
- 捕捉信号
- 忽略信号
6.Socket
跨网络与不同主机上的进程之间通信,就需要Socket通信了
Socket实际上不仅用于不同的主机进程间通信,还可以用于本机主机进程间通信,可根据创建Socket的类型不同,分为常见的通信方式
- 基于TCP协议的通信方式
- 基于UDP协议的通信方式
- 本地进程间的通信方式